Introduction
A while ago, during my first Red Team engagement with Atos, I came up with a tactical anti-eradication approach, which was directly inspired by my former Incident Response experience. The concept is rather obvious and is in no way new, but since I have not seen it being directly brought up and touched upon in the same way I came across it, I thought it would be nice to highlight it, especially for the attention of the defenders out there.
This post is not focused on details of the techniques used for the demonstration purpose (initial foothold, recon, privilege escalation, anti-forensics, lateral movement) as these could as well be different.
It is rather to show how we as attackers can make it harder for defenders to kick us out from their network once they detect our presence in any of the affected systems. And to eventually highlight incident responders the importance and difficulty of full scoping.
Getting right into it
The entire approach basically boils down to using different IOCs when persisting across the target systems (starting with the foothold and continuing with the systems into which lateral moves were made). An additional and preferable step is to erase the forensic footprint revealing the source and the method of lateral movement. Thus, when our presence is detected and acted upon on one of the systems, estimation of the full scope (the full list of systems we attained control of) and therefore full eradication is harder than if we were using the same set of IOCs.
Exemplification
Let’s consider a simple target infrastructure, whereas there is a local network connected to public Internet from behind a NAT. For demonstration purposes, all public IP addresses used here are intentionally incorrect (not compatible with the RFC, for example 333.3.1.2, to keep the examples free from any attribution):

All the systems in the local network have outbound connectivity via 192.168.1.1. Additionally, some services are exposed to the Internet on the public IP 333.3.1.2, with TCP port forwarding set up on the router, e.g.:
333.3.1.2:443 -> 192.168.1.101:443 (MANTIS, HTTPS)
333.3.1.2:80 -> 192.168.1.101:80 (MANTIS, HTTP)
333.3.1.2:21 -> 192.168.1.102:21 (FILESERVER, FTP)
Now, let’s assume we successfully breach the MANTIS server (GNU/Linux) through port 443 by exploiting an outdated version of the Mantis bug tracker web application exposed to the Internet (a successful password spraying attack followed by manual exploitation of CVE-2008-4687). Thus, we attain a foothold in the 192.168.1.101 box. Then we quickly find a world-readable bash script written to perform local MySQL database backup, with the MySQL root user password hardcoded in it, only to quickly discover that it also matches the system root password. So, we have got our initial foothold with escalated privileges.
Now, to persist in the system, we install a Meterpreter ELF binary somewhere in the /usr/bin directory and add it to cron. The implant is configured to connect back via HTTPS to our first CC (Command & Control) server – 444.4.5.6:

Having secured our access to MANTIS, we perform local network recon (e.g. via ping/ARP and manual port probing with netcat) and discover few other systems (e.g. FREDDY, ALICE, BOB, FILESERVER). We can see that FREDDY (192.168.1.105) is running Windows, with ports 445 (SMB) and 3389 (RDP) available. We think of moving laterally, so we dump the MySQL database from Mantis web application. We identify the table holding usernames and their password hashes (48 users in total). We then manage to quickly crack 35 of those hashes offline, and then simply attempt using each of those credentials against FREDDY (Metasploit smb_login auxiliary module). We get one hit (freddy:lion74), which happens to be an administrative user. We can now log in to 192.168.1.105 via RDP. We successfully moved laterally, with high privileges.
And then we realize we want to persist on FREDDY as well, so we can access it even if we lose access to MANTIS. But it would be stupid to use 444.4.5.6 as the CC server for FREDDY. If MANTIS gets contained and examined, we expect the defenders to use the 444.4.5.6 as an IOC (Indicator of Compromise) and examine network traffic going through the gateway to see if more systems are trying to connect to it. Thus, it becomes obvious that it’s better to use another CC for FREDDY – e.g. 555.6.5.1. Also, as an implant, instead of Meterpreter, let’s use an ICMP reverse shell and persist it via WMI, so we diversify our TTPs (Tactics, Techniques and Procedures) even more:
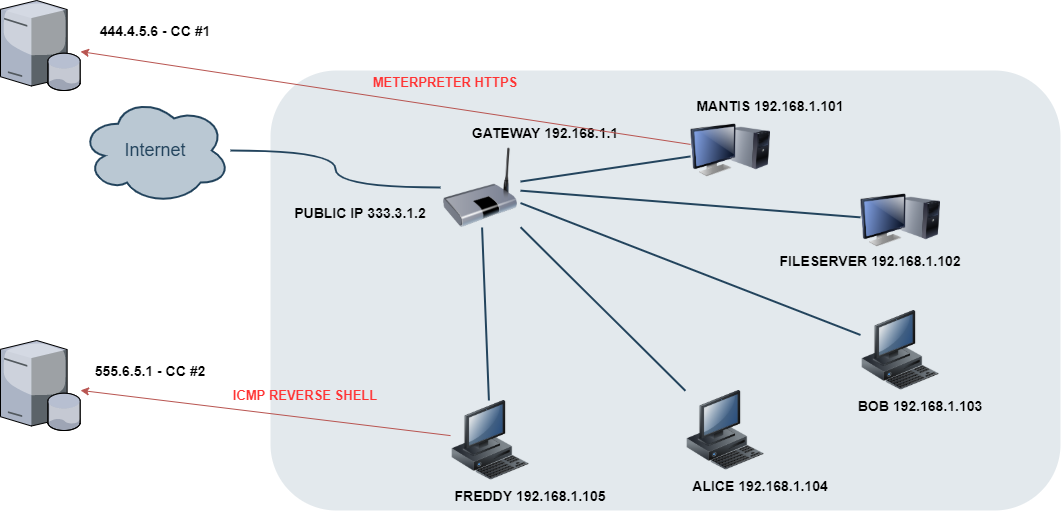
Now, we can erase event logs on FREDDY, trying to get rid of the forensic footprint that could reveal how we got into that system. With this configuration, we decide to continue our further recon and lateral movement from FREDDY instead of MANTIS. If FREDDY gets detected as a source of malicious activity within the network, it will be difficult to discover that it was breached from MANTIS, thus, making it harder to properly scope the intrusion and thus eradicate our presence. And vice versa, if MANTIS is blown, our chances of keeping access to the network via FREDDY will be higher when these two systems do not share IOCs and do not contain forensic evidence of their relation.
“Two is one and one is none”
When I started writing this post, I realized that this subject is an application of the “two is one and one is none” approach. It is a military saying that emphasizes the problem of single point of failure: if we have a mission-critical item, it will inevitably malfunction. When I heard about it for the first time from Rob Fuller[1]
several years ago, I only understood it from the perspective of using two different persistence methods on a single system.
Back then, and in the context of a single system with two persistence methods, I thought doing it was not very practical (thus unnecessary) and a bit risky. Why?
- Unnecessary because I assumed that if our shell got detected, proper incident response would take place, resulting in network containment of the affected system, followed by reimaging (so it would not matter if we had a second backdoor).
- Risky, as performing another persistence method creates more forensic footprint, increasing the likelihood of detection.
Now, having acquired some Blue Team and Red Team experience, I realized my assumptions were idealistic and incomplete.
A good example of how these assumptions turned incorrect was when during one of our team’s engagements, our presence in our foothold system was detected and mishandled by the staff. By monitoring last logon times and .bash_history we realized that one of the administrators noticed a backdoor we installed in an Oracle iPlanet Webserver service (which, by the way, also happened to be our initial foothold vector as well). So, we knew that he knew. But for some reason, instead of fully network containing the system, the administrator simply disabled the Oracle iPlanet Webserver service. Luckily for our team, we already had the root password – while SSH was still available, so we kept access to the server for several more weeks.
Conclusions
From an attacker perspective, it turns out it is not so easy to balance between increasing the risk of getting detected versus increasing the risk of completely losing access when the former happens.
For the defenders out there, keep in mind that full scoping is the key.
[1] https://holdmybeersecurity.com/2017/05/30/part-2-how-to-red-team-metasploit-framework/ https://holdmybeersecurity.com/2017/10/15/part-3-how-to-red-team-setting-up-environment/

By Julian Horoszkiewicz,
Cyber Security Expert, Parttime Lecturer
![]()
![]()
Share this article
![]()
![]()
![]()
![]()