Are privacy-enhancing technologies the holy grail to privacy?
The PET’s promise to unlock collaborative analysis in a secure way, even on regulated or sensitive data
According to Gartner, by 2025, 60% of large organizations will use one or more privacy-enhancing computation techniques in analytics, business intelligence or cloud computing.
PET (Privacy-enhancing technologies) are on the rise. Let’s see why you should have a look at those technologies!
PET are bringing the lacking piece to fully comply with data sovereignty regulations
There is a growing pressure of regulations around Personal Identifiable Information (PII) protection and data sovereignty (e.g. cross border data transfers to Cloud operators), with the difficult exercise for authorities to balance between latitudes to exploit personal data (social, economic benefits) and re-identification risk, or to enable economic benefits from Cloud while ensuring data sovereignty or IP protection.
This is where PET bring their innovation.
From the data sovereignty perspective, the emerging set of privacy-enhancing techniques shift the paradigm.
While data encryption at rest or in transit were already efficiently addressed through existing encryption technologies, data protection in use (data-in-use) was the lacking piece in the triptych, meaning that data needed to be decrypted and thus exposed, at some point of the processing – which was unsatisfactory when done in untrusted environments or by non-sovereign third parties.
Now the question is not anymore where data is computed, or who is operating it, but managing the level of data-in-use privacy risks by choosing the most appropriate technologies to balance between privacy, performance, and usability in a targeted usage.
From the PII perspective, PET are answering de-identification[1] constraints, which gained momentum with EU GPDR, SCHREMS II, or US HIPAA for instance.
GDPR brings clarifications in concepts around identifiability of the data. The identifiability of the data can be seen as a spectrum, from no possibility to link information to individuals, to a continuum of risks to re-identify individuals or groups with more or less ambiguity according to the technique used[2]. By distinguishing anonymization[3], where information cannot be related to identifiable person anymore and is thus not considered as personal data, from pseudonymization[4] where re-attribution is possible, GDPR draw lines to segment and map privacy duties with the relevant PET. PET contribute to privacy-by-default (GDPR)[5], meaning providing systematically the highest level of privacy to the minimum subset of data required for a specific purpose.
PET are enabling the data provider, the code provider, the infrastructure owner/operator, and the data consumer to meet their compliance & business targets while sharing data requiring high level of privacy. PET are mentioned as solutions for a new role of ‘trusted data intermediary’, envisioned in EU data Governance Act, which is part of the upcoming EU regulations on data. Experimentations are conducted amongst others by authorities[6] or leading financial institutions[7] to test application-level encryption, trust mechanism for data sharing and develop post-quantum encryption[8].
PET have matured, making the promise become more concrete to enterprises
Under the “data-in-use privacy” banner, PETs are in fact various technologies applicable with various maturity level (see Gartner Hype Cycle for Privacy).
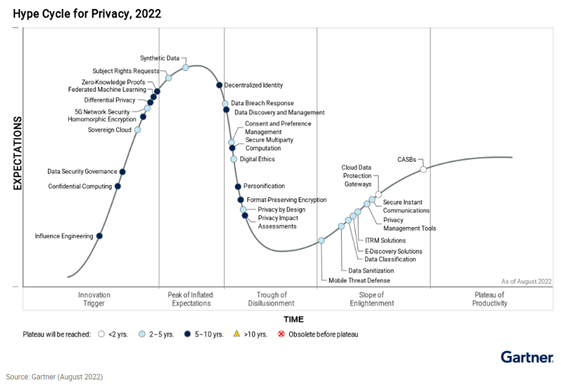
With the simplified model below[9], let’s have an overview on PET that can be combined to increase data privacy, whether applying to the data itself, its exploitation, or the underlying infrastructure. Very basic targets or issues driving the choice of PET are highlighted respectively in green & red.
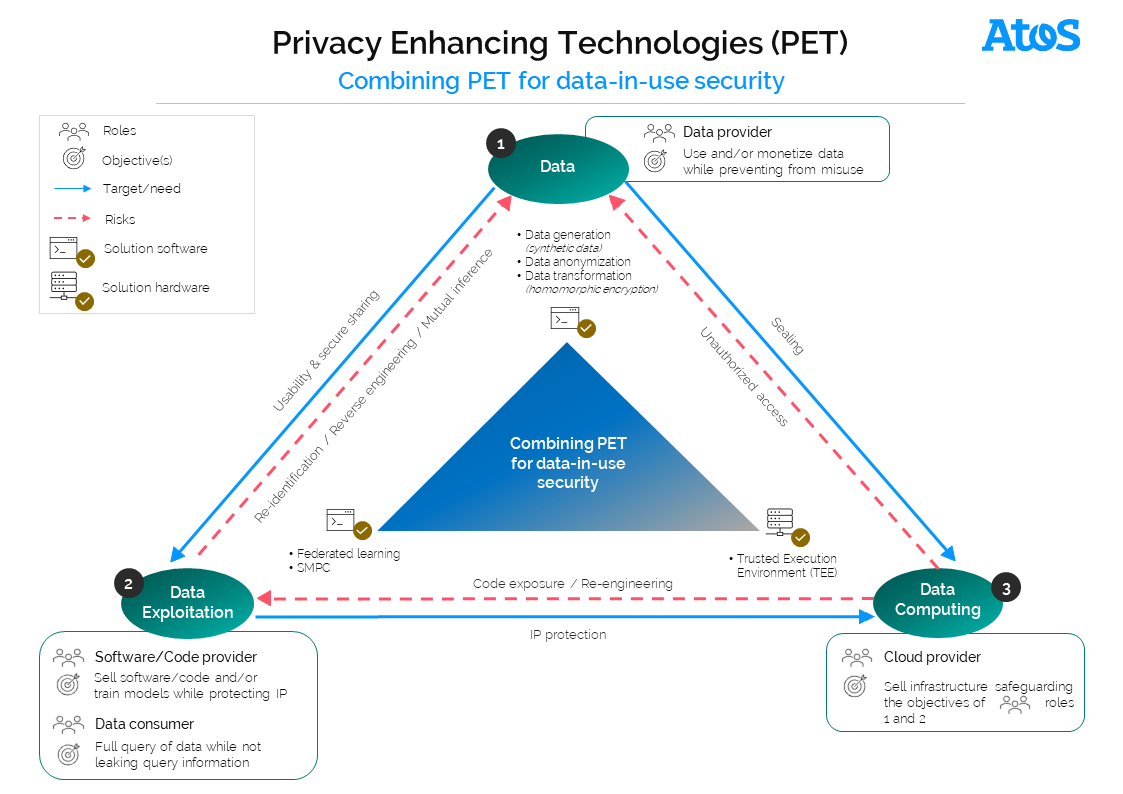
From the data owner perspective, the target is to use and/or monetize data while preventing from misuse
To do so, he can rely either on techniques transforming the data (like Homomorphic Encryption), anonymizing data, or surrogating real data (like Synthetic data).
About data anonymization techniques, ENISA stands that “a generic anonymization scheme cannot be applied to all use cases and provide full and unlimited protection”[10] but “should be adapted according to the type of data, the processing operation, the context and the possible attack models”. Technics like differential privacy (generating on-the-fly statistical noise on the data), are quite commonly considered as a viable, balanced mean to achieve data privacy and usability in AI model training and analytics.
Nevertheless, the precision of analysis is inversely proportional to the level of protection[11], which makes mandatory to have expertise to maintain privacy.
By 2030, synthetic data generation could completely overshadow real data in AI-training (Gartner[12]) despite the security risks to have reverse-engineering on ML model.
On the cryptographic side, promising technologies like homomorphic encryption, enabling computation of data while it remains in an encrypted state, are maturing from performances & calculation perspectives (limited functions, intensive computation, data size increase), and are already used – often in combination with other PET for collaborative models.
From the data exploitation perspective, software/code provider objective is to sell software/code and/or train models while protecting Intellectual Property. Data Consumer will be attracted by the opportunity to fully query data while not leaking query information.
For data sharing ecosystems, Secure Multi-Party Computation (i.e. SMPC) offerings are now available on the market, allowing parties to compute a function jointly on combined data, with good performances, while keeping their own inputs secret. Federated Learning enables to train AI in a decentralized way – requiring no training data transfer. Nevertheless, model inversion or inferences attacks remain possible.
Hardware-based secure enclave models (based on TEE, standing for Trusted Execution Environment) can also be used to solve trust issues between ecosystem players, by isolating and protecting code/application as well as data from host system’s owner (integrity “in use” : no access or visibility on the running process outside the TEE instance, data integrity guarantees, and strong key protection). Implementation may be not trivial, with significant changes on legacy applications.
If PET can be used separately, the trend is to combine them according to the use case, to optimize privacy insurance, by utilizing each technique where its strengths lies and/or where it overcomes the other PET’s weaknesses. This can be seen in such examples as: adding differential privacy (i.e, noise) on top of federated learning to reduce the risk of reverse-engineering of data sets through trained model’s parameters[13], or combining cryptography with Differential privacy[14]. Several technical variables have to be considered for each use case – such as the type of data, the number of players in the ecosystem, the size of the data set, or the need to keep data centralized or on the contrary to treat it without moving them.
From technological availability to customer implementation
The offering landscape is still disaggregated.
Hyperscalers are proposing most of the PET’s building blocks, for instance, adding TEE to their Iaas offerings (also known as “Confidential computing”) or proposing crypto libraries. They are also issuing integrated platforms, like PPML (Privacy-Preserving Machine Learning) platform tackling collaborative use cases, and they develop partnerships with Data Security pure players either to integrate specific advanced capabilities or for vertical use cases[15]. Those pure players are themselves part of the heterogenous offering landscape. Integrators are entering the game, proposing combined offerings with pure players[16] or services on top of Hyperscalers platforms.
At that stage, entering the PET field might be not trivial to enterprises. How to succeed?
“The exact choice of techniques depends on the use case at hand”[17].
When choosing a PET technique, keep in mind the following points:
- Enterprises should first assess their privacy risks, evaluate their coverage through the most common methods (like data masking) and evaluate the balance between additional privacy-risk coverage and implementation complexity.
- Enterprises should anticipate the need for post-quantum encryption when it comes to protect data privacy on the long term (e.g : banking), while this is not mandatory for short term sensitive data (like IOT),
- When privacy target is :
- to de-identify, data masking technics are well-known,
- to exploit data collectively, PET focusing on the way the data is processed are starting point (SMPC, FL), if necessary privacy budget can be enhanced by combining those PET with statistical noise and/or cryptography,
- to process securely code and data in untrusted environment, TEE or FHE can be used, keeping in mind the potential impacts at applicative level.
- Combine techniques according to their strengths (e.g: searchable encryption being more performant than FHE – Full Homomorphic Encryption for searches),
- Perform threat modeling & Evaluate the solution agility / resilience to attacks (e.g : keys with attribute-based encryption in case of data corruption, possibility to select a type of encryption scheme per data partition …).
- Do not forget to respect basic principles in the implementation: encrypt as soon as possible & decrypt as late as possible, externalize key management, use of certified Key Management Systems completed if necessary, by Hardware Security Modules and evaluate robustness of crypto libraries.
[2] https://nvlpubs.nist.gov/nistpubs/ir/2015/NIST.IR.8053.pdf
[3] GDPR, Recital 26
[4] GDPR, Art.4
[6] E.G : Eurodat program
[7] Banque de France, JP Morgan
[8] https://www.whitehouse.gov/briefing-room/statements-releases/2022/05/04/fact-sheet-president-biden-announces-two-presidential-directives-advancing-quantum-technologies/
[9] By Atos
[10] ENISA Data Protection Engineering report
[11] The royal Society – From Privacy to partnership
[12] Is Synthetic Data the Future of AI?
[14] Privacy-Enhancing Cryptography to Complement Differential Privacy
[15] E.g : Google with French healthcare startup Arkhn
[16] E.g : Thales / Enveil
[17] Gartner “Top Strategic Technology Trends for 2022:Privacy-Enhancing Computation”
Posted on: March 1st

Barbara Couée
Digital Security Portfolio Manager
Follow or contact Barbara:
![]()
Share this article
![]()
![]()
![]()
![]()


